Her şeyi biraz daha iyi anlatmak için tabletimde bazı resimler yaptım. O kadar hoş olmadıkları için üzgünüz.
Karıştır
Karıştırmazsak, birbiri ardına değeri (float, double, integer, short integer, ...) saklarız. . Böylece, her değişkenin kendisi sürekli olarak bellekte saklanır. İkinci bir değerin ilk biti, birinci değerin son bitini takip eder. Karıştırma kullanırsak, tüm değişkenlerin ilk biti ardışık olarak boşlukta depolanır, ardından ikinci bit vb.
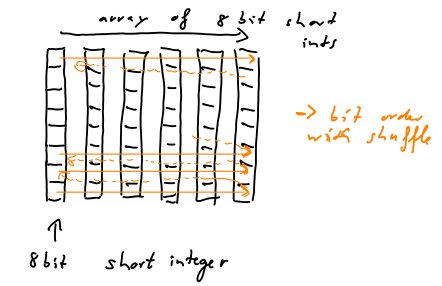
Yukarıdaki şekil altı adet 8 bitlik tamsayıdan oluşan bir diziyi göstermektedir (daha az boyama işi olduğu için sadece 8-bit). 8 bölmeye bölünmüş dikey siyah kutular, 8 bitlik tamsayıyı temsil eder. Soldan sağa doğru olan turuncu oklar, bitlerin karıştırma ile nasıl saklanacağını gösterir.
Şimdi bazı örnek değerleri varsayıyoruz: 4, 2, 4, 5, 7 ve 6 değerlerine sahip bir dizimiz var. Aşağıdaki şekilde gösterilmiştir. İlk satır, ondalık gösterimi gösterir. Aşağıdaki matris ikili gösterimdir. Her ikili sütun, ilk satırdaki ilgili ondalık sayıyı temsil eder. Kırmızı oklar normal saklama sırasını gösterir. Turuncu oklar, karıştırılmış saklama sırasını gösterir.
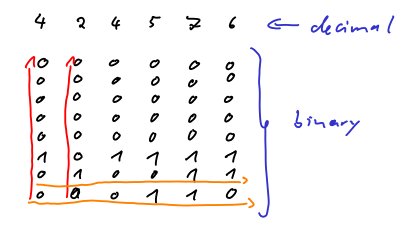
Artık hafızadaki bitlerin sırasını yazabiliriz. Renk kullanmak istedim. Bu nedenle, başka bir resim elde edersiniz:

Her bir değerin ikili temsilinin başında pek çok sıfır var (çünkü biz çok düşük değerlere sahiptir). Bu durumda karıştırma uygundur çünkü aynı sayı / koşul (= 0) ile dolu uzun bir bitişik bellek parçamız var.
Düşük sayılar olmasaydı, ancak birbirine yakın daha yüksek sayılar (ama) olsaydı, 0'larla (sıfırlarla) dolu uzun bitişik bir bellek bölümümüz olmazdı, ancak altı 1 ve sonra altı 0 olabilir. Genellikle netCDF dosyalarında çok daha büyük dizilerimiz vardır. Birbirine oldukça benzeyen 100 x 200 x 30 x 365 değerlerine sahip 4 boyutlu bir dizi diyelim. O zaman bellekte sık sık 2,19 x 10 9 bitişik 1'ler veya 0'lar olur, bu da sıkıştırma için oldukça iyidir.
Ancak, komşu değerler önemli ölçüde farklılık gösteriyorsa, karıştırma bir iyi fikir.
Bölme
Sıkıştırılmamış bir dosyamız varsa (= yığın yok; veya büyük bir yığın), bir n-dim dizisi bellekte bitişik olarak depolanır: ilk başta tüm değerler dizinin ilk satırının (ilk dizin), bellekte bitişik olarak saklanır; sonra bir sonraki satıra gidiyoruz (ikinci indeksi bir artırıyoruz) ve ikinci satırı bitişik olarak belleğe yazıyoruz; ve benzeri.
Ayrıca son dizinle başlayıp tam tersi de yapabiliriz ... - programlama diline ve satırların ne olduğunun tanımına bağlı olarak ve sütunlar . Ancak prensip aynıdır.
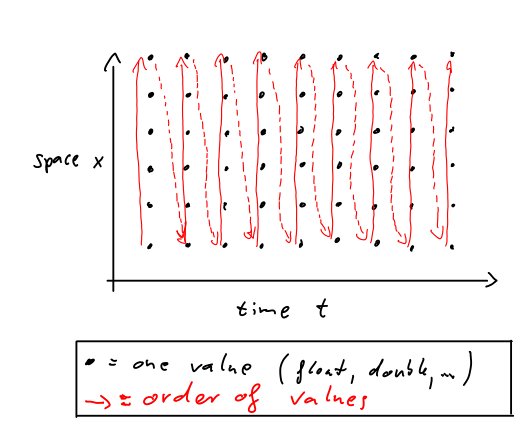
Aşağıdaki şekil, bir uzaysal ve bir zamansal boyuta sahip 2 boyutlu bir değişken için bir örnek göstermektedir. Kırmızı oklar, verilerin bellekte nasıl hizalandığını gösterir. Siyah noktalar, 2 boyutlu dizimizdeki ayrı değerlerdir.
Şimdi, bir zaman dilimi (tüm uzamsal değerler) çıkarmak istiyoruz. verilerimizden bir zaman adımında) ve bir uzay dilimi (tek bir konumdaki tüm zamansal değerler). İkinci durumda bir zaman serisi elde ederiz (bir zaman serisi model verisi olabilir). İlk durumda, mevcut durumun bir resmini elde ederiz (bir harita için olabilir). Aşağıdaki şekildeki mavi ve yeşil işaretler zaman ve mekan dilimlerini göstermektedir.
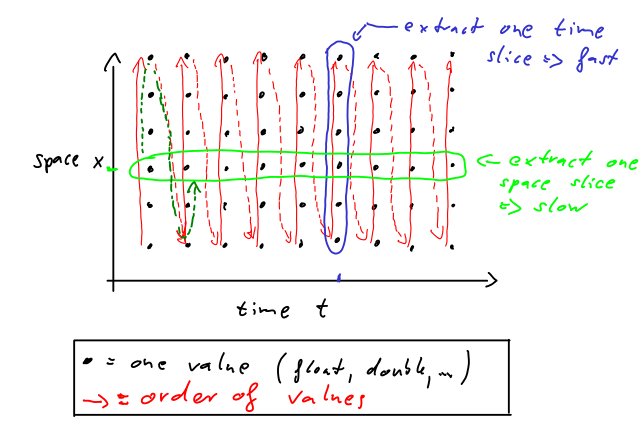
Zaman ve uzay dilimi arasındaki fark şudur. Değerler bellekte bitişik olarak saklandığından zaman diliminin ayıklanması hızlıdır. Boşluk dilimleri daha fazla zaman alır çünkü yalnızca her bir altıncı değer çıkarılır. Bu örnek, fazladan iş / zaman harcaması düşük mü? Bununla birlikte, 4 boyutlu büyük bir değişkenimiz varsa, zaman dilimi çıkarma, uzay dilimi çıkarımından daha hızlı olacaktır.
Verileri sıkıştırdığımızda, onu parçalara ayırabiliriz. Bu, büyük dizi değişkenimizi alt dizilere böldüğümüz anlamına gelir. Kullanıcı için dışarıdan aynı görünüyor. netCDF-4, verileri sıkıştırdığımızda ancak bir yığın oluşturma modeli tanımlamadığımızda otomatik olarak yığın oluşturur.
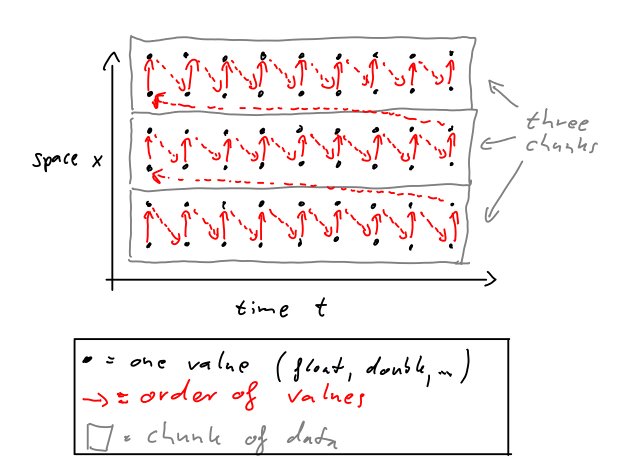
Aşağıdaki şekil, verilerimizin üç parçaya bölündüğü bir örneği göstermektedir. Kırmızı oklar bellekteki değerlerimizin hizalanmasını gösterir. Bu sadece örnek bir hizalamadır.
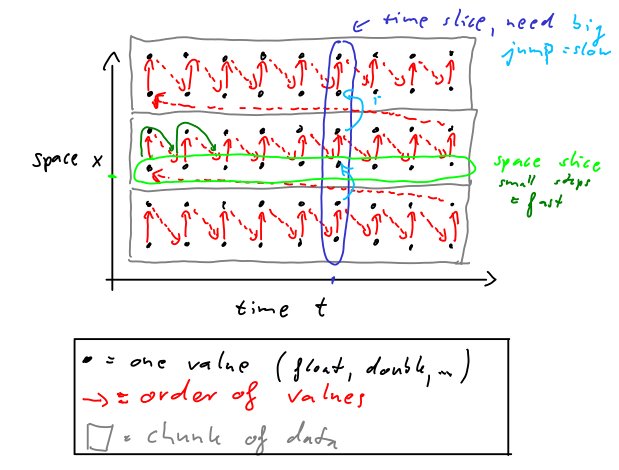
Şimdi, zaman ve uzay dilimlerini tekrar çıkarıyoruz (aşağıdaki şekil). Yeşil ve mavi yine dilimleri gösterir. Burada, boşluk diliminin çıkarılmasının öncekinden çok daha kolay / daha hızlı olacağını görüyoruz. Ancak, zaman diliminin çıkarılması daha fazla zaman alacaktır.
Ayrıca, yığın boyutlarını değiştirdiğinizde sıkıştırma farklı olacaktır. . Arka plan, Shuffle” bölümünde açıklandığı gibi benzerdir: Hangi değerlerin birbirine komşu olduğuna bağlı olarak, biri veya diğeri uygun olabilir.
Şimdi sorunuza gelelim: En iyi yığın boyutu seçimi nedir?
kullanıma odaklanın
Verilerinize bağlıdır kullanım ve kalıba erişirsiniz. Zaman serilerini sık sık belirli konumlardan çıkarırsanız, parçaları bir konuma karşılık gelen değerlerin birbirine yakın olacak şekilde bellekte hizalanmış şekilde tanımlamak daha uygun olabilir.
Ancak dikkatli olun, cdo gibi bazı yazılımlar netCDF verilerine her zaman aynı şekilde erişir - işlem sırasında onunla ne yaptığınıza bakılmaksızın. Bu nedenle, dosyaya doğrudan C- veya Fortran-netCDF4 rutinleri aracılığıyla değil, başka bir yazılım aracılığıyla erişiyorsanız, en iyi yığın oluşturma modeli ne yapmak istediğinize değil, yazılımın nasıl yapar ... . Örneğin, bazı yazılımlar verileri her zaman önce uzamsal boyutlar boyunca okuyabilir, ancak siz zaman boyutu boyunca veri isteyebilirsiniz.
sıkıştırmaya odaklanma:
Sıkıştırılmış dosyanın boyutu değişir yığın düzeni ile. Durum, Karıştırma bölümünde anlatılana benzer. Veriler zaman boyutunda sıkıştırmak için daha etkili ise, yukarıdaki örnek şeklimdeki yığınlar dosya boyutu için uygun olabilir (örneğin, uzayda yüksek değişkenlik ancak zamanda düşük değişkenlik).
Bölünme özeti
En iyi yığın boyutu seçimi, erişim modelinize, kullandığınız yazılıma, verilerinizin kendisine ve erişim süresi ve depolama alanı üzerine odaklanmanıza bağlıdır.
Sıkıştırma düzeyi
Sıkıştırma düzeyi seçimi, amacınıza bağlıdır. Verileri (bir arşivde veya herhangi bir yerde) depolamak ve mümkün olduğunca küçük olmasını istiyorsanız, sıkıştırma düzeyi 9'u kullanabilirsiniz.
Verilere sık sık ve hızlı erişmek istiyorsanız, daha düşük bir sıkıştırma seviyesi seçmelidir. 4'e kadar sıkıştırma seviyeleri kullanıyoruz. Bunun üzerinde dosya boyutundaki azalma (bizim için) çok düşük olduğundan ötesine geçmek için bir nedenimiz yok.
Örnek: Şu anda bir okyanus modeli ile çalışıyorum. Model alanımızda çok fazla arazimiz var (kabaca 1/3). Düzey 1'in sıkıştırılması, dosya boyutunu yaklaşık% 95 oranında azaltmak için yeterlidir. Ancak bu özel bir durumdur.
özet:
İstediğiniz özelliklere genel bir bakış vermeye çalıştım. Kesin seçim, özel kullanım durumunuza bağlıdır ve genelleştirilemez. Senin için cevabım çok geç olabilir ama umarım bazılarına yardımcı olur. Bana göre, bağladığınız belge geçmişte çok yardımcı oldu.